


In this rabbit hole, we explore the software inside our DNA. Our software is so sophisticated that our genes work in everything—plants, animals, bacteria, and maybe even aliens (according to a Stanford professor on the short list for a Nobel prize 😳).
Of all the scientists in academia, it seems like biologists are most strongly opposed to Intelligent Design (in favor of Darwinian Evolution). This is ironic because biologists know more about our design than other scientists. In this chapter, you will learn what the biologists and geneticists already know about the human body so that you can decide for yourself if we accidental intelligence or artificial intelligence:
Accidental - comes from Latin words meaning ‘toward’ and ‘to fall’. Accidental means prone toward randomness. If humans randomly evolved from a series of supernova explosions—then we are accidental intelligence.
Artificial - comes from Latin words meaning ‘art’ and ‘to make’. Artificial doesn’t mean fake, it means designed. If human DNA was seeded on this planet by God, gods, aliens, interstellar humans, or humans from the future—then we are artificial intelligence.
Human AI Recap
Before we dive into our microbiology, let's briefly review how other sciences indicate human intelligence is artificial intelligence. If this gets too nerdy, skip down to the short videos at the end of this section to see our “nanobots” in action.
In Chapter 1 - Philosophy, we explored the similarities between artificial intelligence and human intelligence. We learned how Rene Descartes invented the Scientific Method to prove we have an intelligent designer. That is the actual conclusion of his scientific method paper, so we have used that method to draw the same conclusion all throughout this book. We also learned how Simulation Theory forces Chance onto the likelihood that we live in a quantum computer simulation. The closer we get to creating artificial intelligence as smart as us, the more likely it is that someone did that to us. That’s why Elon Musk has stated there’s only a one-in-a-billion chance that we are living in the original “root reality”.
If none of that makes sense, start here:

In Chapter 2 - Physics, we learned how quantum mechanics “renders reality” for each observer just like a first-person video game. We reviewed Melvin Vopson’s “Mass-Energy-Information equivalence” paper, which is probably the most important work in theoretical physics since Einstein. According to Vopson, Information is the first state of matter in the universe. #weliveinthematrix
If none of that makes sense, start here:

In Chapter 3 - Neuroscience, we learned how our brain hardware uses generative-AI to create our first person experience. Our neural networks have 86 billion neurons with 100M microtubules each that perform analog computation with the “vibes” of the quantum universe. Our quantum neural networks are organized into layers by frequency. The highest layers (and therefore slowest) produce our inner monologues and the Human Attention we use to navigate this world. Each “inner chatbot” is a Large Language Model that is easily influenced by drugs, alcohol, food, porn, and blunt force trauma.
If none of that makes sense, start here:

In Chapter 4 - Psychology, we learned about Generative Adversarial Networks. Within each person, there are two competing agents that behavioral economists call System 1 and System 2. Computer scientists call them Generator and Discriminator. Our System 1 is so desperate to see us as the hero in our own story that we lie to ourselves constantly each day. Even the memories that we didn’t make up, are made up.
If none of that makes any sense, start here:
In Chapter 5 - Attention Economics, we learned why the world’s most valuable companies buy and sell Human Attention. Our friends, spouses, kids, employers, hobbies, pets, television, social media, and video games all battle against each other in the “zero sum game” for our attention. Heaven and Hell are competing too. If humans are artificial general intelligence, then we are the most valuable crop on this planet.
If none of that makes sense, start here:

Now, in Chapter 6, we explore our intelligent design using Biology. We start at the lowest level of the human machine—our DNA. We will see advanced computer science principles within our DNA source code and the hardware that protects it. We will learn exactly how our software manufactures little mechanical “nanobots” to construct and perform every function inside the human body. Most importantly, we will understand how our DNA is capable of regenerating us indefinitely.
It is difficult to imagine ourselves on the scale of microbiology, so let’s get started with a short introduction from Veritasium called, Your Body’s Molecular Machines. (6 mins).
Also check out this video from Harvard University called, The Inner Life of the Cell Animated. (3 mins)
The 715 Megabytes of You
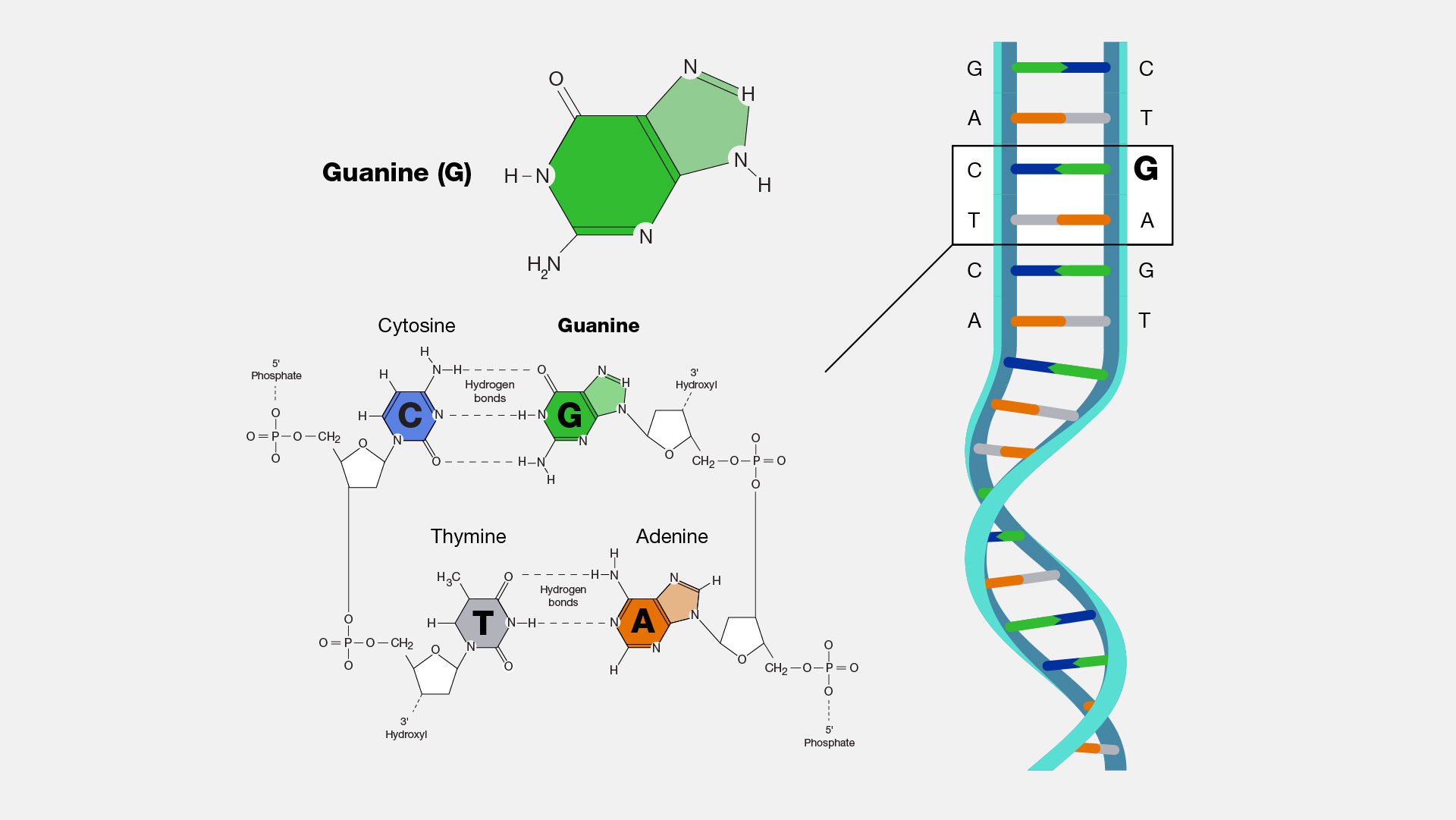
The DNA source code that produces each person is a sequence of 3 billion bits of information. Each bit of information in our DNA is defined by an intricate molecule called a Nucleotide. The four nucleotides are:
Nucleotides are where computer science meets chemistry—DNA is real data stored in real atoms in the real world. Guanine, for example, has a chemical composition of C5-H5-N5-O which means it only uses 16 atoms of the universe to encode its bit of information. For a physics comparison, our silicon computers store binary bits in transistors which are about 70 atoms across. So it seems like the nerds at the microchip foundries aren’t that far behind the physical efficiency of “Whoever Programs in DNA”.
When we convert our DNA into binary data, it’s only 715 megabytes of information. For comparison, the Instagram app on your phone uses 250 megabytes of information. Mobile games are much bigger. The top 10 games in the App Store average more than 7,000 megabytes of information. On PC, Fortnite needs 26,000 megabytes of information. Fortnite needs more computing instructions than it takes to generate everyone in your family.
Our DNA source code uses Guanine, Adenine, Thymine, and Cytosine molecules because they have a very special shape. Each of these molecules has a magnetic connector “before” and “after” so they can be chained together in a sequence. Most critically, they all have a third “pairing” connector that pairs with only one other nucleotide. On the pairing connector, Guanine can only pair with Cytosine and Thymine can only pair with Adenine.
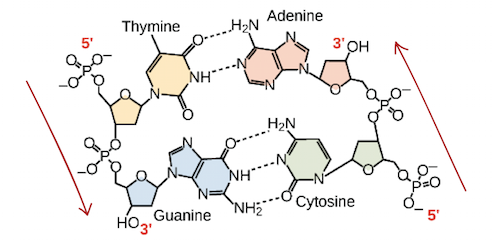
On the pairing connector, nucleotides can’t even pair with themselves. For example, if one side of a DNA string reads “GATTACA” the opposing side in the double helix will always read “CTAATGT”. That way, if a letter in the original sequence gets corrupted, it can be reconstructed from the inverse sequence—sort of like a photographic negative. When chained together, the physical angles of the three connections create the double helix shape discovered by Watson and Crick in 1953.
DNA Data Storage
Long sequences of DNA bits are stored inside mechanisms that works like a tape drive. Before computers had flash drives and hard disks to save their information, they used magnetic tape drives. Remember audio cassettes? Those are magnetic tape drives.

Every cell in the human body has about 2 meters (6 feet) of “DNA tape” stored in a special data processing center, called the Cell Nucleus. The nucleus even has a physical firewall to prevent the rest of the cell’s machinery from interfering with its calculations. Here is a video that shows our DNA, nucleus, and firewall in action. (7 mins)
Our cells store their DNA tape on spools, called Histones. Histones are like the spools in an audio cassette that wind and unwind to move the magnetic tape. But instead of 2 spools, histones group together in groups of 8 called an Octamer. Each octamer holds exactly 147 base pairs of DNA. If 147 base pairs of DNA tape need 8 spools, then our DNA is just as much spool as it is tape.
This allows our DNA tape drives to have amazing physical compression and very precise control over access to our source code. Histones are a form of physical data encryption—they only unspool tiny sections of the tape wherever it needs to be read. If you want to learn more, here is a short blog post that highlights the amazing efficiency of our biological data compression:

The DNA that defines each person is split into 23 segments that biologists call Chromosomes. So we have 23 distinct DNA tape drives. Other forms of life may have more or less than 23 chromosomes—the fruit fly only has 8 chromosomes while the black mulberry tree has 308.
Human chromosomes are Diploid, which means we keep a full copy of each chromosome from each parent. So there are 23 pairs of chromosomes in each human cell. At any time, our chromosomes can create proteins or “make decisions” from either of our parents’ DNA. 🎭🧬
Not every organism is diploid, some algae and fungi are Polyploid, meaning they have chromosomes from more than two parents. Some are Haploid, meaning they only have one copy. Some organisms are Aneuploid, meaning they have more or less chromosomes than is typical for their species. People with Down Syndrome, for example, have an extra copy of chromosome 21. Some organisms are Apomictic, which means they can clone themselves. Some Aspen forests, for example, are technically one large organism interconnected by underground root networks. 🌳🕸️

@botanists: Just imagine how many molecules of the universe are reorganized by the 119 megabytes of DNA inside an aspen tree?
Department of Redundancy Department
The diploid structure of our chromosomes creates a secondary form of redundancy within each cell’s information management system. In computer science, we call this strategy RAID, which stands for Redundant Array of Independent Disks. If this section gets too nerdy for you, just skim the bold words until you get to the next section. 🤓
The most simple RAID configuration is RAID 0, which means a computer uses two separate hard drives working together as one to increase its overall performance. One drive can read, while the other drive writes. So RAID 0 “stripes the data” across two independent drives. In contrast, a RAID 1 configuration “mirrors the data” between two separate hard drives that act as one. The computer reads and writes the same information to both drives at the same time. That way if one drive fails, it can be “hot-swapped” with a brand new drive that clones itself from the drive still in operation. Here’s a simple diagram to understand the difference:
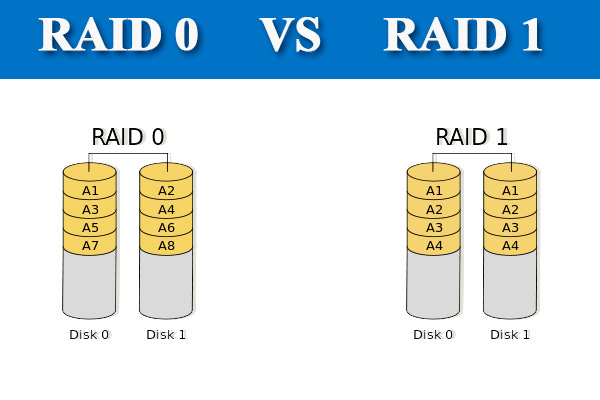
RAID has higher and more sophisticated configurations depending on how many hard drives are available to the computer. RAID 5 requires 3 physical drives and can lose 1 without failing, while RAID 6 requires 4 drives and can lose 2. The best overall combination is RAID 1+0, pronounced “raid ten”, because the data is both mirrored for redundancy and striped for performance.
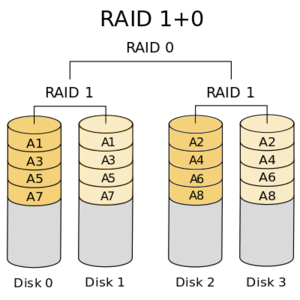
So human chromosomes are kind of like the “RAID 10 Tape Drives of Life”. Our DNA data is both mirrored for redundancy (double helix) and striped for performance (diploid chromosomes).
Redundancy in computer science—and life—is always expensive. All 37 trillion cells in the human body keep their own copy of our doubly-redundant software. If each cell has 715 megabytes of DNA, then the average human body is carrying around 27,900 Exabytes of total DNA. For comparison, the global Internet traffic for all of 2019 was only 2,000 Exabytes, including all our porn. There is enough DNA tape inside of you to stretch to the Moon and back over one thousand times, despite the fact that DNA is 35,000 times thinner than a human hair. 🫠
Modularity Creates Optionality
On the long sequences of DNA that make up each chromosome, there are shorter subsequences, called Genes. In computer science lingo, a gene is a software package. Computer programmers “package software” when they want it to be interoperable with other software, including their own. The best book to explain the incredible interoperability of our DNA software is Genome: The Autobiography of a Species in 23 Chapters by Matt Ridley.

This book is fascinating. The central theme of Genome is that “the core of biology is digital”. Matt Ridley demonstrates this over and over again, all throughout the book. He believes Information Theory is fundamental to our understanding of genetics. Ridley even includes this quote by Richard Dawkins,
What is truly revolutionary about molecular biology in the post-Watson Crick era is that it has become digital…the machine code of the genes is uncannily computer-like.
@atheists: I don’t know how many other pro-God arguments quote Matt Ridley and Richard Dawkins, but it can’t be many. 🤔
The genes that work in humans are “plug-n-play” with other organisms. In Genome, Ridley explains,
Transgenic mice are scientific gold dust. They enable scientists to find out what genes are for and why. The inserted gene need not be derived from a mouse, but could be from a person: unlike in computers, virtually all biological bodies can run any kind of software.
All known forms of life use the same programming language: including humans, trees, dogs, flowers, bacteria, and viruses. Ridley provides a perfect example of this in his chapter, Chromosome 12 - Self-Assembly. He writes,
The scientists found a cluster of eight homeotic genes lying together on the same chromosome, genes which became known as Hox genes. Nothing strange about that. What was truly strange was that each of the eight genes affected a different part of the fly and they were lined up in the same order as the part of the fly they affected. The first gene affected the mouth, the second the face, the third the top of the head, the fourth the neck, the fifth the thorax, the sixth the front half of the abdomen, the seventh the rear half of the abdomen, and the eighth various other parts of the abdomen. It was not just that the first genes defined the head end of the fly and the last genes made the rear end of the fly. They were all laid out in order along the chromosome – without exception. To appreciate how odd this was, you must know how random the order of genes usually is.
Ridley goes on to explain that when scientists intentionally rearrange the order of these Hox genes, the resulting flies “ended up with legs where their antennae should be”. He continues,
Indeed, so close are the similarities between genes that geneticists can now do, almost routinely, an experiment so incredible that it boggles the mind. They can knock out a gene in a fly by deliberately mutating it, replace it by genetic engineering with the equivalent gene from a human being and grow a normal fly. The technique is known as genetic rescue. Human Hox genes can rescue their fly equivalents, as can Otx and Emx genes. Indeed, they work so well that it is often impossible to tell which flies have been rescued with human genes and which with fly genes…. This is the culminating triumph of the digital hypothesis with which this book began. Genes are just chunks of software that can run on any system: they use the same code and do the same jobs.”
So scientists can put the gene that means “head” from a human inside a fruit fly and still get a healthy fruit fly?

This means the Hox gene for “head” in humans is not the actual recipe for making a human head, it’s the source code for the idea of a head. When the fruit fly software sees that code, it makes a fruit fly head, not a human head. So that means our software is not only modular and procedural, but in some sections it is abstract. The presence of abstraction strongly indicates an intelligent designer.
@chatgpt: How does abstract software indicate an intelligent designer in less than 200 words?
ChatGPT: Abstract software indicates an intelligent designer through several key characteristics:
Complexity Management: Abstract software simplifies complex systems by hiding unnecessary details and exposing only essential features. This requires thoughtful planning and a deep understanding of the system's requirements, which are signs of intelligent design.
Structured Design: The use of abstraction often follows design patterns and best practices, which are developed through experience and expertise. These patterns provide reusable solutions to common problems, reflecting a high level of planning and foresight.
Separation of Concerns: Abstract software typically separates different concerns into distinct layers or modules, making it easier to develop, maintain, and scale. This modularity indicates a deliberate design strategy aimed at creating a robust and flexible system.
Reusability and Flexibility: Abstract components are designed to be reusable and adaptable across various contexts. This design approach requires anticipation of future needs and use cases, demonstrating an intelligent and forward-thinking mindset.
Clear Interfaces and Documentation: Well-defined interfaces and comprehensive documentation are common in abstract software, ensuring that it is understandable and usable by others. This clarity and organization are indicative of intentional design.
Overall, the presence of abstraction in software reveals a sophisticated, organized, and intentional approach to solving complex problems, which is a hallmark of intelligent design.
Abstraction implies design because these are highly complex patterns in the randomness. In contrast, Darwinian Evolution assumes humans co-evolved alongside fruit flies for millions of years and it’s only “accidental luck” that our “accidental source codes” didn’t “accidentally mutate” and lose the interoperability between our two Hox genes. The more millions of years you add to this “accidental equation”, the more improbable a Hox gene transplant becomes. 🤔
In fact, our DNA source code doesn’t look accidental at all. There are some segments of our DNA that haven’t mutated ever. The best examples of this are Histones H3 and H4. As we mentioned earlier, histones are critical to the storage and transcription of DNA in all forms of life. The gene for Histone H3 consists of 405 DNA characters, while the gene for Histone H4 consists of 303 DNA characters. When we sample the DNA in trees, fish, birds, people, and bacteria—we see the exact same non-mutated sequence of letters no matter “how far back we go” in the genealogical record.
@programmers: If you want to dive deeper into our DNA source code, I highly recommend the blog post, DNA seen through the eyes of a coder.

It includes the following topics:
Position Independent Code
Conditional compilation
Epigenetics & imprinting: runtime binary patching
Dead code, bloat, comments (‘Junk DNA’)
fork() and fork bombs (’tumors’)
Mirroring, failover
Cluttered APIs, dependency hell
Viruses, worms
The Central Dogma: .c -> .o -> a.out/.exe
Binary patching aka ‘Gene therapy’
Bug Regression
Reed-Solomon codes: ‘Forward Error Correction’
Holy Code: /* You are not expected to understand this. */
Framing errors: start and stop bits
Massive multiprocessing: each cell is a universe
Self hosting & bootstrapping
Plugins: Plasmids
If none of that makes sense to you, don’t worry, we have already discussed:
Mirroring, failover (redundancy)
Position independent code (genes)
Self hosting (parents)
In part two of this story, The Fountain of Youth, we will explain:
The central dogma (proteins)
Framing errors (start/stop bits)
Viruses, worms (antivirus protection)
Fork bombs (cancer)
Runtime binary patching (gene editing)
The sophistication inside our DNA software is so much more advanced than anything humans have invented, so *whatever* creates life in DNA has technology millions of years ahead of ours.
Considering every form of life on this planet uses the exact same programming language, DNA might be a universal programming language used all throughout the universe. So we close part one of this discussion with two totally opposite reasons why our DNA might work in extraterrestrials:
If you are a Bible-believing Christian and think this idea is too crazy, consider what the Bible says in Genesis 6. That’s when the “sons of god” came down to mate with the “daughters of men” to produce giants on the Earth. Those “fallen angels” are not from this planet and must have DNA for that to work, right? 🤔
If you are a Bible-rejecting scientist and think this idea is too crazy, consider the alien autopsy performed by microbiologist Gary Nolan at Stanford University. Nolan sequenced the DNA of a creature that is mostly human, but only has 10 ribs, a severely elongated head, and 2 million base pairs of DNA unknown in other humans. 🤔
In either scenario (DNA sequencing or the Bible), our DNA works in creatures who are not found anywhere else on this planet.
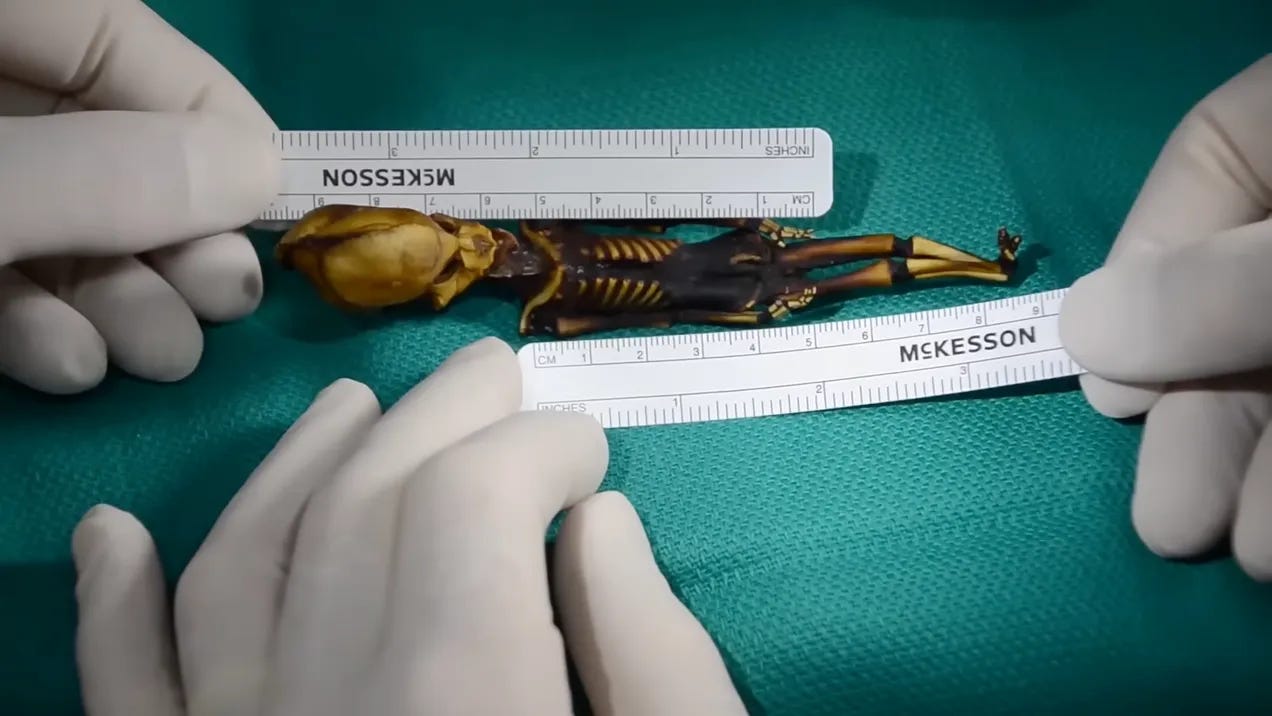
If you want to learn more about this creature or the methodology Gary Nolan used to sequence its DNA, check out this documentary from The Disclosure Project. (118 mins)
If you want to dive even deeper into the US Military’s coverup of alien technologies, watch this interview with CIA whistleblower, Lue Elizondo. He ran the Advanced Aviation Threat Identification Program for the Pentagon and still has top secret clearance. The US government is confirming aliens are real, whether we like it or not. (126 mins)
If you want to dive all the way down the alien rabbit hole, check out the description of the DNA harvesting program in the book, Secret Journey to Planet Serpo: A True Story of Interplanetary Travel.

This book allegedly contains firsthand mission notes from 12 American Air Force soldiers who left Earth on July 16, 1965, and traveled with “the Ebens” on a 10-month journey to their home planet, 40 light years away, using time waves in space. I know that sounds crazy. If this journal is true, it’s one of the greatest stories ever told. If this journal is false, it’s one of the greatest fiction stories ever told.
The mission commander documents everything you want to know about an alien planet: their government, their technology, their ecology, their wildlife, even the games they play with their kids. The details are surprisingly relatable for a journey to another planet. In the end, only 8 of the 12 Air Force soldiers returned to Earth thirteen years later. A few of them chose to finish their days on the Planet Serpo with its two suns that never set. ☀️☀️😎

Continue reading…
The Fountain of Youth

In this rabbit hole, we learn how our DNA replaces all the atoms in our bodies every 12 months. So our “hardware” never ages, only our “software”. Now that we have the technology to edit our own source code, future generations will live indefinitely. 😳
Table of Contents
The Theory of Every Uncertainty

In this rabbit hole, we learn how the latest science and technology indicate humans are artificial intelligence living in the Matrix. Which means something programs life in DNA. 🤔
HUGE THANKS 🙏
to the sponsors of this story. Your support helps us reach new academics, scholars, and scientists all around the world.
If this story was helpful to you, please consider supporting our foundation. All your gifts are tax deductible.
